CLIP
CLIP工作自提出就立马火爆全场,它的方法出奇的简单但效果却出奇的好,很多结果和结论都让人瞠目结舌。比如CLIP模型的迁移学习能力非常的强,这个预训练好的模型可以在任意图像数据集上取得不错的效果,而且它几乎是zero-shot的(无需再这些数据集上做训练)。作者做了超级多的实验,它们在超过30个数据集上做了测试,包括OCR、视频动作检测、坐标定位、细分类任务等。值得一提的是,在所有这些结果中最炸裂的一条是,它在不使用imagenet训练集(128万)的情况下直接做zero-shot推理就能达到和之前有监督训练好的resnet-50取得相近的效果。在CLIP这篇工作出来之前这是不可想象的。
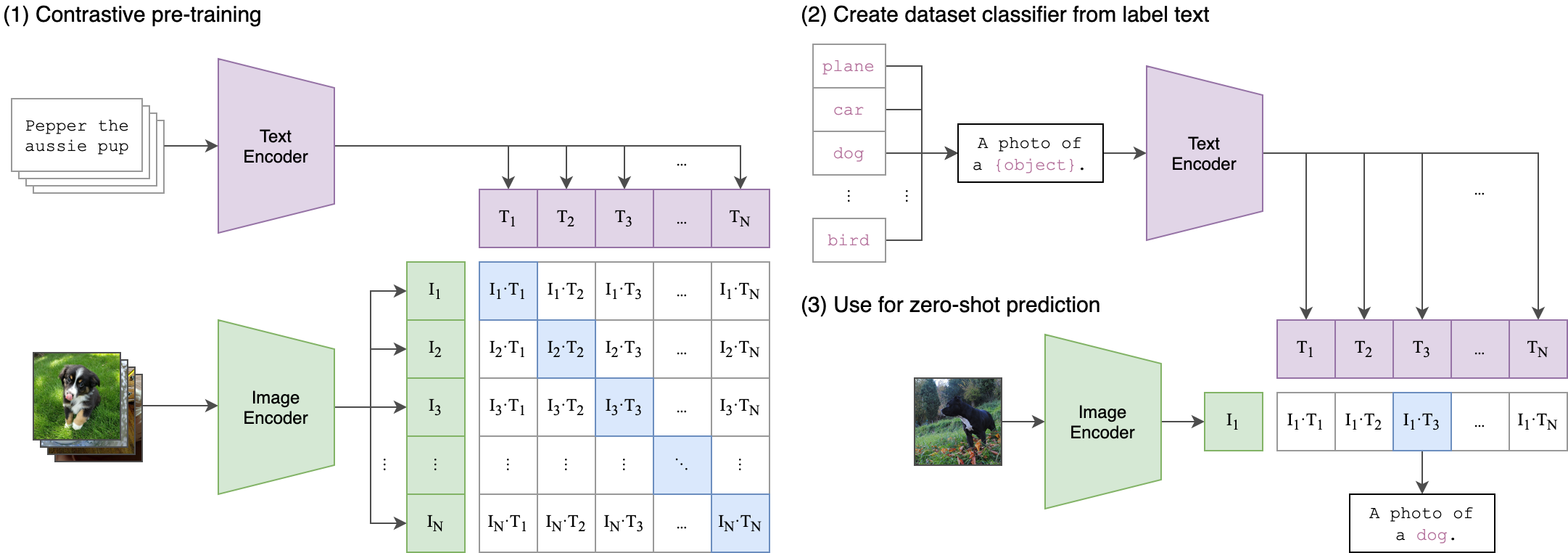
预训练流程:
总览:通过自然语言处理的监督信号我们可以训练一个迁移效果很好的视觉模型。
模型的输入是一个图片和文字的配对,图片通过图片的编码器得到一个特征,编码器可以是resnet也可以是ViT;文字也会通过一个文本的编码器,从而得到一些文本的特征。假设每个training batch中都有 n 个图像文本对,那么我们可以得到 n 个图像特征和 n 个文本特征,CLIP就是在这些特征上做对比学习。
而我们知道,对比学习非常的灵活,它只需要一个正样本和负样本的定义,然后在损失函数中进行相应的常规操作即可。这里的正负样本也非常明确,配对的一个图片文本对就是一个正样本,也就是特征组合矩阵中,对角线上的是正样本。剩下的非对角线上的对儿就是负样本。
一旦有了正负样本,就可以通过对比学习的方法训练起来,完全不需要任何手工的标注。(不过无监督对比学习仍然需要非常大量的数据。)所以openai专门收集了超大规模的数据集,它里面有4亿个图片和文本的配对(用搜索引擎通过文本搜的图,然后做的配对)。数据质量非常好,这也是CLIP预训练为什么能这么强大的原因之一。
zero-shot推理:
CLIP模型预训练之后只能得到视觉和文本上的特征,并没有在新数据集上进行训练和微调。那么怎么在没有分类头的情况下做推理呢?论文的方法比较巧妙,他们用了prompt template。以imagenet为例,CLIP先把imagenet的1000个类变成一个个句子,格式是:
A photo of [object] .
A photo of plane .
A photo of apple .
......
然后这1000个类对应的句子通过我们预训练好的文本编码器得到相应的1000个特征表示,这里需要指出的是,直接把类别词 plane, apple 送入文本编码器也是可以得到特征表示的,但是由于图片每次训练看到的都是一个句子,所以最好和训练保持一致。而且作者后面还提到,怎么设计prompt template 句子也是有讲究的,所以论文后面提出了 prompt engineering 和 prompt ensemble 两种方式去进一步提升模型的准确率而不需要重新训练这个模型。然后在推理的时候,不管来了任意一张图片,只需要把图片输入图片编码器得到相应的特征,然后用图片特征和文本特征去算cosine similarity。最终最相似的文本特征对应的类就是图片的分类类别。
关于 prompt:
基于prompt的学习最近非常火,prompt 是在微调或直接做推理的时候用的一种方法,而不是在预训练阶段,所以我们并不需要那么多的计算资源。prompt 翻译过来有很多的含义,这里有点对应中文中的意思 “提示”,也就是文本的 引导作用。为什么要做 prompt engineering 和 prompt ensemble 呢?作者举了两个例子,一个是单词的多义性,如果做文本匹配时只用一个单词去做文本的特征抽取,会面临多义性的问题,如 crane(起重机,丹顶鹤),总的来说就是如果只用一个单词会经常出现歧义性问题。另外,在预训练中,我们匹配的文本一般都是一个句子,很少是一个单词,因此最好在测试和推理阶段也使用句子。于是作者就使用了一个非常简单的办法 —— 提示模板 (prompt template)。而且如果提前知道一些信息(如知道数据集是动物相关,可以用 template: a photo of {}, a type of animal. ),这对 zero-shot 的推理非常有帮助。
而 prompt ensemble 则是多用几个模板,多做几次推理,然后把结果综合起来。论文中用了 80 个。
更强大的是,CLIP并不局限于1000个类,原则上可以进行任意类别的分类,只需要添加相应类别对应的prompt template即可。但这在之前的分类任务中,类别是严格限制在1000个上,那么模型是无法将没见过的图片分类正确的。CLIP彻底摆脱了categorical label数量的限制 ,也就是在CLIP框架下我们无需预定义标签列表,只需要给相应类别对应的文本即可。
而且CLIP不只可以用于识别物体,它还把图片和文字的语义联系到了一起。所以CLIP学习到的特征语义性非常强,迁移效果也非常好。在openai官网还给了这样一个例子:在imagenet上之前训练好的resnet101(1000分类头)是76.2的准确率,CLIP训练出来的VIE-LARAGE也是76.2的准确率;但当换到imagenet v2,imagenet rendition,objectnet等不同domain数据集上,resnet101准确率下降的非常快,而CLIP并没有,它的效果始终都非常高。
基于CLIP的应用
StyleCLIP(ICCV oral):CLIP + StyleGAN 语言控制图像生成;(效果震撼!)
CLIPDraw:语言控制生成简笔艺术画;(如果是艺术家画的没准能卖个好价钱。)
VISION AND LANGUAGE KNOWLEDGE DISTILLATION:CLIP 做物体检测;
Constrastive Language-Image Forensic Search:视频检索(是否出现过某个物体,某个人),监控视频检索;能直接去做OCR了;
Q.E.D.


